
OO第一单元总结
前言
在三周的磕磕绊绊中,也算是顺利完成了oo第一单元的三次作业。面对久仰大名的oo,虽说的确很累,但也收获良多。
第一次作业
题目描述
读入一个包含加、减、乘、乘方以及括号(其中括号的深度至多为 1 层)的单变量表达式,输出恒等变形展开所有括号后的表达式。
需求如下:
- 处理括号
- 处理指数
- 计算加,减,乘
- 化简合并得到结果
基本思路
对于输入的一个表达式,我主要分为两步进行处理:
第一步:解析表达式,得到后缀表达式
第二步:计算后缀表达式,得到结果
具体实现
首先我对输入的表达式进行了一波预处理,主要就干了两件事:去空格,连续的加减号变成一个符号
然后,开始解析表达式,我在课程组在training中提供的递归下降算法的代码基础上,根据题目要求做了稍微修改,得到后缀表达式(不得不说,课程组给的代码真是救大命)
这里要提一句,由于第一次作业经验不足,我将指数在解析表达式阶段处理,也就是解析时读到一个^,就将前面的式子乘对应指数遍,比如我读到
(x+1)^3,我就会处理成(x+1)*(x+1)*(x+1),一个^还好,一旦指数嵌套,由于我存的时候没有化简合并,就会有爆时间和爆内存的风险,也是导致了我在第二次作业强测的第二个点挂掉。所以指数处理还是要在第三步计算时实现。现在我们要对上一步得到的后缀表达式进行计算来得到最终结果。本次作业主要自己写的也就是这一部分。具体实现方式是我新建了一个Calculate类用于实现计算操作。
我们可以发现最终得到的结果是一个多项式,而其中每一个单项式都是
系数*x^指数的形式(要注意输出时判断一下系数和指数的值看能否省略或化简),那么由于底数都是x,我们就可以用一个HashMap<Integer,BigInteger>来存储多项式,即HashMap<指数,系数>。比如3*x^2+4*x^5我们就可以存成HashMap<(2,3),(5,4)>同时由于指数作为key,我们也可以更容易的实现同类项的合并。之后,由于我们是对后缀表达式做处理,所以可以用
ArrayList来代表一个栈,里面存储多项式.这样在后缀表达式中读到数字或者x,我们就将其存入栈中;读到符号就取栈顶的两个多项式进行对应的加、减、乘的计算得到结果再存入栈中,当处理完后缀表达式后,栈中只剩下一个多项式,就是最终的结果了。
UML图
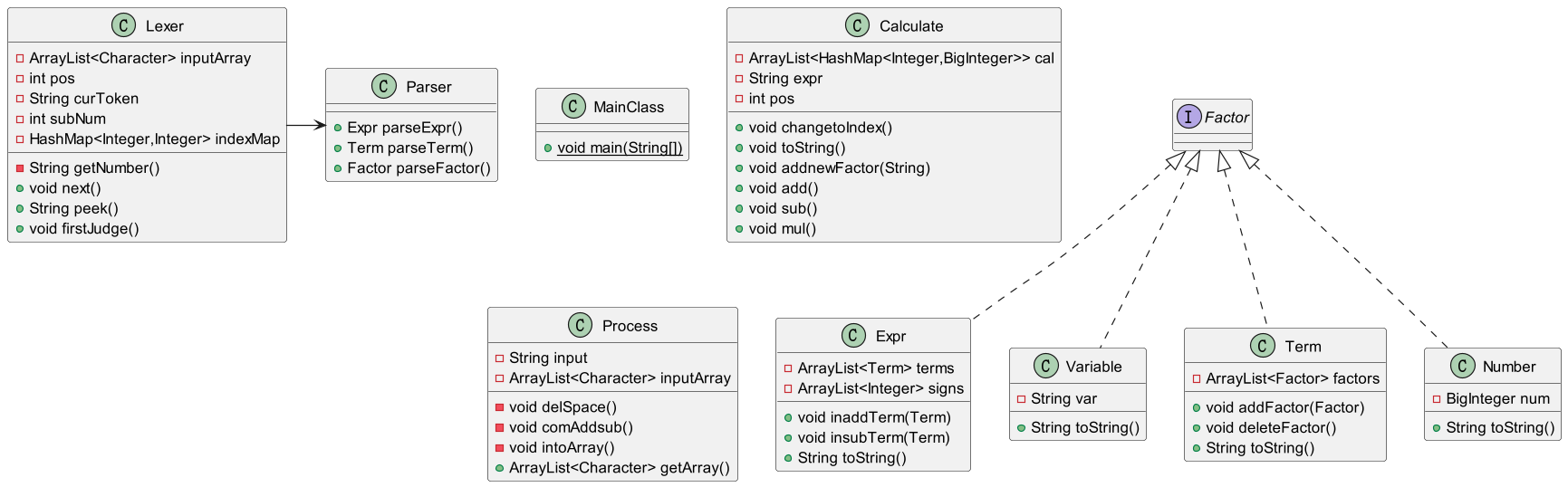
优化方式
由于第一次作业相对比较简单,所以优化方式也不多,在进行同类项的合并之后只需要注意一下将多项式中的首个负项放在最前面即可
Bug分析
本次作业强测以及互测都没有出现bug,同时在互测中也没有测出别人的bug(满心期待的把别人代码丢到我的评测机里跑,跑了半天也什么bug都没有)
在本次作业中我也是第一次搭建评测机完成自动化测试,我在往届学长的评测机代码的基础上进行了稍微修改也搞出了一个自己的评测机,还算成就感满满。
第二次作业
第二次作业我认为是三次作业中最困难的一次,新增功能不少,同时处理指数函数对于刚刚入门oo的我也有不小的难度
新增需求
- 支持处理嵌套多层括号
- 新增指数函数因子:
exp(因子)^指数 - 新增自定义函数因子
基本思路
整体流程和第一次作业一样,还是先解析得到后缀表达式,再计算后缀表达式并化简合并输出最终结果。
- 对于处理嵌套多层括号:在第一次作业中的递归下降算法便足以解决这个问题,无需新增代码
- 对于自定义函数:我在预处理阶段从字符串层面对于自定义函数进行替换
- 对于指数函数因子:对calculate类进行重构,改变数据结构来存储新的多项式,同时改变加,减,乘的方法。
具体实现
自定义函数处理:我新建了一个
SelfDefineFun类用于存放输入的自定义函数。随后在表达式预处理中,我遍历表达式,如果读到f, g, h那么就将找到完整的函数交给SelfDefineFun类处理,并利用在自定义函数类中写的toString方法得到处理之后的字符串。这里要注意两个点:
第一个点是要注意嵌套自定义函数的情况,使用递归处理即可
第二个点是注意替换x的时候不要把exp中的x也换掉
解析表达式修改:由于本次新增指数函数,所以就在递归下降中加入
parseExp方法,位置和解析括号位置相同。此外,我对于
exp()后面可能存在的指数的处理方法是将指数乘进括号内,比如exp(x)^2就处理成exp(x*2),这样就可以使我在最终输出前所有的exp()都没有指数,方便我对exp()从字符串层面进行同类项合并重构计算类:这个可真是下了大功夫,也是写了很多面对过程编程的代码,本来打算重构的,但是第三次作业刚好用到了一部分,也就没有全改掉
和上次一样,我发现最后的多项式由相同形式的单项式组成,每个单项式都是
系数*x^指数*exp((多项式)),于是我用TreeMap<String, Integer>来存储单项式,TreeMap<TreeMap<String, Integer>, BigInteger>来存储多项式,再和上次一样用一个ArrayList来作为计算的栈存放多项式。具体计算就是和上一次作业大致类似,就是需要重新写加、减、乘方法来实现对指数函数的计算与合并
输出:我的优化均在输出时实现,也就是在输出时判断指数和系数的值看是否需要输出,以及对exp()内的情况进行判断来确定输出方式
UML图
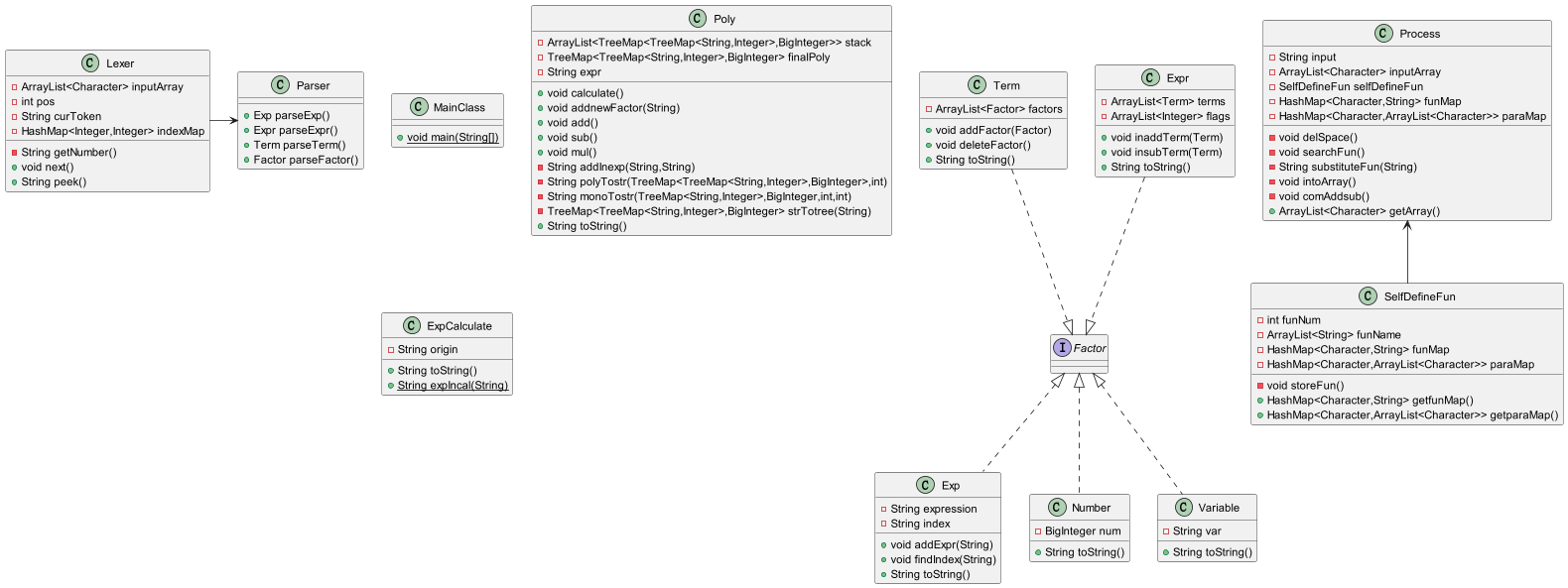
优化方式
本次优化还是有很多方面需要考虑的,我做了如下实现:
- 第一个负项提到最前面
- 对于exp内部相同的进行合并
exp((因子))->exp(因子)exp((系数*因子))->exp(因子)^系数
除了我做的这些优化之外,还有人做到了将exp()内的公因式提取到括号外,以及将一个exp()拆成两个exp()相乘。由于考虑到正确性优先以及实现其他优化对代码改动较多,我没有继续优化。
Bug分析
很不幸,我的本次作业在强测中挂掉两个点:
第一个点是因为处理指数函数的方式错误导致面对(((((((((((x^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8这样的数据时出现了MEMORY_LIMIT_EXCEED错误。
第二个点是由于在优化时我将exp()内的系数提到括号外,但由于我之前所有的exp()都是不带指数的,所以我之前对exp(因子)都是直接采取subString(4, exp.length() - 1)的方法获取exp()内的因子,这也导致了优化后出现指数时获取因子错误。
在互测中被hack的点和强测的第二个点错误方式一样。
但同时,我在互测中也成功hack到别人三个错误:
- 由于优化时去掉括号错误导致出现
exp(-x) - 提取公因式时将负数提出到指数位置
- 处理自定义函数时在读入其中exp()内的因子出现错误
前两个点均是通过自己捏数据来hack到的,第三个错误是利用我的评测机跑出来的,自己的评测机第一次在互测中发挥作用,感觉很不错。
第三次作业
第三次作业确实挺简单的,抱着死磕两三天的心态开始第三次作业,结果一个晚上搞完了。虽说轻松却没有了第二次作业的激情,让这周像过博客周一样。
新增需求
- 自定义函数定义时可以出现之前定义过的其他自定义函数
- 新增求导因子
基本思路
- 对于自定义函数的改变很简单,就是在替换的时候再调用一下就好
- 求导因子我是通过化简后对需要求导的多项式的每个单项式分别进行求导处理,因为单项式有通项形式,所以实现较为容易
具体实现
这里就说说对求导的处理吧
解析阶段:和exp()一样,我把dx()当做整体存进后缀表达式中,同时dx()里面也是后缀表达式形式
计算阶段:求导无非就是对一个表达式也就是一个多项式求导,那么多项式求导就是其中的每个单项式分别求导再相加。
我们知道单项式的通项形式为
系数*x^指数*exp((多项式)),那么这个东西求导就是前导后不导加后导前不导,也就是dx(系数*x^指数*exp((多项式)))等于系数*dx(x^指数)*exp((多项式)) + 系数*x^指数*dx(exp((多项式)))而对于幂函数和指数函数求导又有各自的法则,就很容易处理了。
UML图
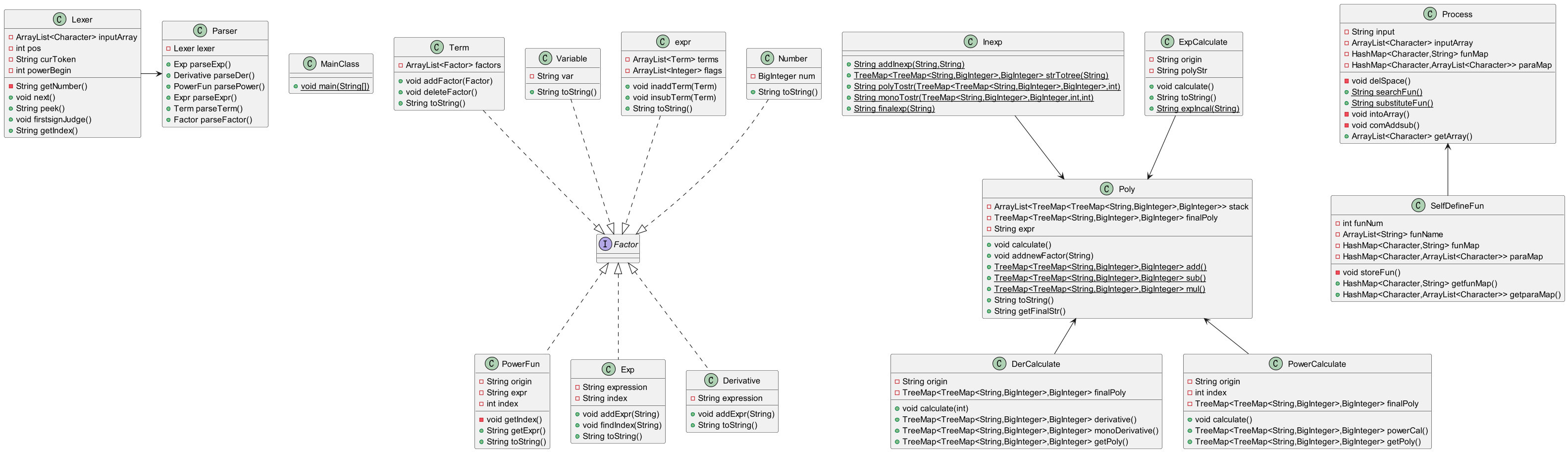
优化方式
由于第三次作业和第二次的输出形式可以说是一模一样,我在第二次的优化方案上并没有新增其他优化
Bug分析
和第一周一样,我在强测和互测中均没有出现错误,同时互测房内也都没有出现bug
心得体会
持续三周的第一单元这么快就过去了,现在想想,前两周冥思苦想无从下手的样子仿佛还在眼前。oo不仅让我学到了面向对象编程的思想,让我的代码思路更清楚,一切为对象服务、接口封装,一段码该干嘛就干嘛,不用乱加其他功能,同时也提升了我对较大规模代码的整体设计能力以及debug能力。在之前我编写代码时可能想一点写一点,但现在,我会拿出一张纸,好好构思好好设计,思考每个类的功能以及他和其他类的关系,争取让我的设计更优雅,我的代码更清晰。
同时,在第三周和第四周任务量很少的时候,我也老会觉得空唠唠的,可能甚至习惯了前两周的高强度oo时光了吧。所以,已经期待着下一单元了,继续探索,继续战斗,继续痛苦并快乐着!
未来方向
对于第一单元修改的建议,我个人看法有以下两个方面:
- 感觉可以修改一下cost机制,有时候很简单的数据过不了cost限制,一些相对复杂的数据又不会被限制(虽然我没仔细研究过cost机制,但在hack别人的时候是这种感受)
- 可以调整一下第三单元难度,从第二单元到第三单元落差有点太大了,感觉可以增加一些难度
这就是我的第一单元总结了,oo第一单元完结,撒花!