
oo-Unit3
前言
经过了上一单元电梯的折磨,我个人感觉这次的JML相比之下还是比较容易的吧
架构设计
容器的选择
本次单元作业的绝大多数指令都是通过id来寻找对应的tag,Person还有Meessage。
以Person为例,如果把所有的Person都放在一个List容器里,那么我们每次查找都需要遍历一遍容器,算法复杂度为O(n),很容易出现TLE。
所以我选择了HashMap作为存储容器,将id作为键值,这样可以保证每次查询都能以O(1)的复杂度完成。

算法设计
由于本单元的各个方法之间相对独立,所以我就逐个分析一下我优化的方法。
第一次作业
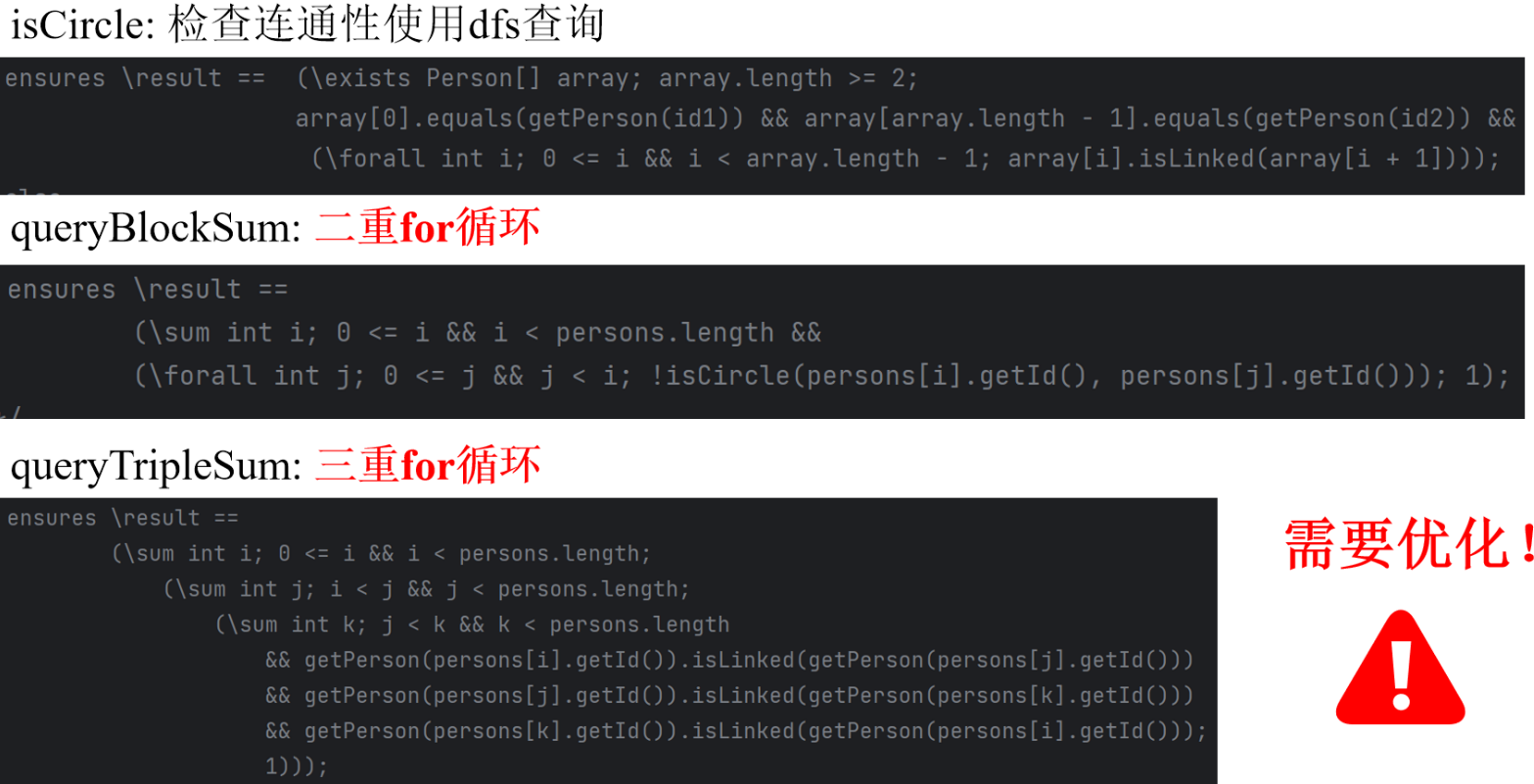
第一次作业中呢,有三个较为复杂的方法:isCircle,queryBlockSum和queryTripleSum。那首先就单纯看JML我们可以看到queryBlockSum是二重for循环,queryTripleSum是三重for循环。这种O(n^2)及以上的时间复杂度肯定是不行的,所以我们可以通过并查集和随时维护来进行降低时复杂度。
并查集
首先我的并查集中有三个容器: parent存放每个节点的根节点,rank存放每个节点的秩,graph存放与每个节点直接相连的各节点。然后再通过路径压缩,按秩合并和关系删除来降低这两个方法的时间复杂度。
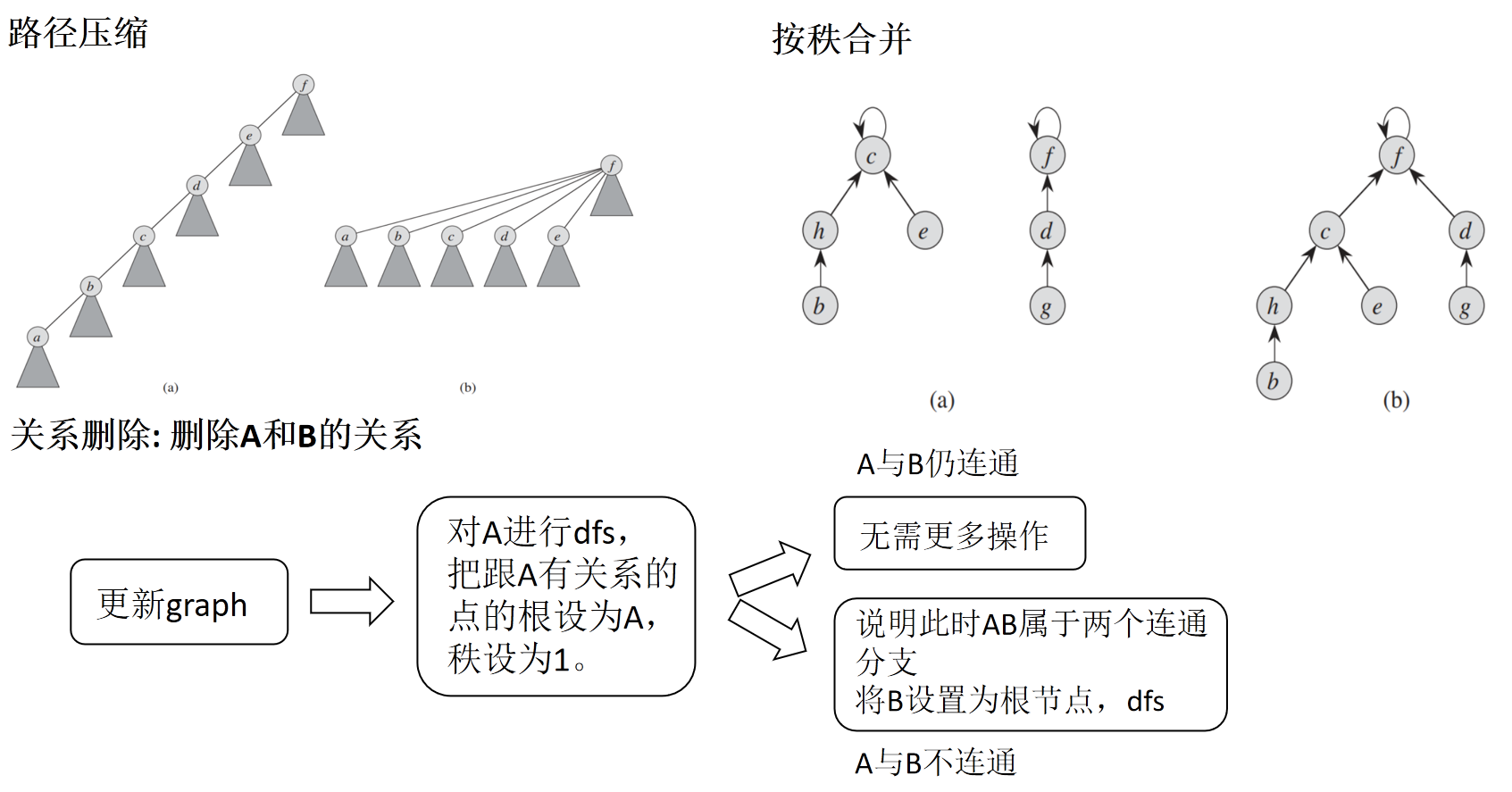
路径压缩的意思就是我们在找一个元素的根节点的时候,比如这张图我们要找a的根节点,于是a找到b,b找到c,一直找到f,那我们就把这一路上所有节点的根节点都设为f。这样做的目的就是在一个连通分支内所有元素的根节点都是一个元素,这样我们只需要比较两个节点的根节点就可以判断他们是否连通了。
public int find(int id) { |
然后是按秩合并,就是说我们要将并查集的两个连通分支连起来的时候,总是将秩较低的树的根指向秩较高的树的根。这样可以一定程度上减短查找路径。
public void union(int id1, int id2) { |
最后是关系的删除。比如我们删除AB之间的关系,需要对并查集做一下更新,这时候有两种情况就是删完关系之后AB仍连通或者AB不连通了。那操作方法就是我们先更新一下graph然后对Adfs,把跟A有关系的点的根设为A,秩设为1。这样我们就可以建立一个以A为根节点的联通分支,然后如果这里面有B,那无事发生,我们不需要再操作B了。但如果这里面没有B,那就说明AB不再联通,此时我们就再也B为根节点,重复刚才对A的操作就可以更新完并查集了。
public void del(int id1, int id2) { |
对于queryTripleSum方法,我们在每次增删关系后维护,这样虽然每次维护时的时间复杂度从O(1)变成了O(n),但是查询时的时间复杂度从O(n^3)变成了O(1),大大降低了时间复杂度。
第二次作业

然后第二次作业依然是一些新增了Tag和一些指令,对于复杂度是O(n^2)及以上的一定需要优化。
这里有一个方法是queryTagValueSum右边是直接按照JML写的方法,他的时间复杂度是O(n^2),我听说不少同学因为直接就是这么写的,没有维护这个方法然后强测挂了一个点。那左边是每次删改关系时都要维护,乍一看好像是两个都是嵌套for循环,但其实左边这个维护时只是遍历所有的Tag,双重for循环也只是找到所有Tag而已,所以时间复杂度依然是O(n)。
其他的方法比如queryBestAcquaintance,因为他复杂度是n,所以我没维护他。queryCoupleSum就是每次增删改关系时先调用一下queryBestAcquaintance,然后根据两个人的老couple和新couple通过一些if判断语句来维护coupleSum,可以将复杂度降为O(1)。
还有这个搜索最短路径就可以直接bfs,广度优先搜索。我是使用双向bfs做了一点优化。
第三次作业
然后第三次作业的方法复杂度最多就是O(n),我个人没有做算法优化。
测试方案
黑箱测试
黑箱测试是指测试应用程序的功能而不是其内部的结构和运作,测试者只需要知道什么是系统该做的事情。意思差不多就是使用数据点或者评测机测试程序,例如中测强测就都是黑箱测试。
白箱测试
白箱测试又叫结构测试,测试者需要知道程序的结构和处理算法,按照程序内部逻辑设计测试用例,检测主要执行通路是否都能按预定要求正常工作。我认为就是类似于JUnit实现的单元测试。
其他测试
单元测试
单元测试是指对软件中的最小可测单元进行检查,这里我理解的就是对每个方法进行测试。例如我们在本单元编写的JUnit测试功能测试
我理解的功能测试其实就是黑盒测试。我的作业也主要是进行黑盒测试。将数据输入多个程序,比对输出是否一致,进行只关注输入输出是否正确的功能测试。集成测试
集成测试是将不同的模块集成为一个整体进行测试。主要测试各模块之间的数据通信。压力测试
顾名思义,就是对程序提供压力数据,测试程序的性能表现。我在本单元的hw10中进行了压力测试。
hw10在于同学对拍的时候发现偶尔有些数据我会跑的很慢,经过不断缩小数据范围,排查出基本上是
qtvs的问题,然后生成只含apar这些初始化指令和qtvs指令的大量数据来进行压力测试,基本确定问题所在。回归测试
回归测试是对软件的原来状态重新测试,以确保软件在迭代出新版本之后,仍能符合之前的要求。具体来说,可以拿上次作业的测试程序与测试数据来测这次作业。我没有进行回归测试,感觉没什么必要,上次作业涉及的部分基本上没有功能实现上的改的。
数据构造
因为有评测机去检测程序的正确性,所以我们手动构造数据时基本就只需要检测程序的性能即可,也就是单个指令的优化做的到不到位。
我的构造思路大概是这样:
先加很多个人和关系
针对要测试的指令复杂度O(n)中的n,尽量增大n
再添加要测试的指令达到我们的目的。
性能与Bug
在性能方面,我是采取能维护就维护的原则,将时间复杂度较高的方法全都进行优化,以避免在强测中出现TLE。
很幸运,本单元三次作业我在强测和互测中均未出现bug,其实很大程度上也得益于本单元作业的整体架构比较简单,不会像第二单元出现各种奇奇怪怪的bug。
在写本单元作业前,就听说要做到规格和实现分离,一开始还并不太懂什么意思。但是完成了本单元作业之后,就可以体会到这句话的意思:规格的目的是限定我们的行为,但不固定我们具体的行为,我们并不需要完全按照JML的朴素算法完成要求,而是可以通过各种算法来做到性能优化。
关于JUnit
本次作业的JUint在前两次作业也是卡了我很多次,但其实JUnit的编写也是有一点套路:
- 首先构造数据点
- 然后在每次操作指令完成后,都测试一下
- 每次测试就是按照jml逐条验证
这样的JUint测试就可以很好地检测该方法是否完全符合JML的要求和限定,也是属于白箱测试的优点。
心得体会
总的来说,我感觉在第三单元,按照jml编写代码确实让每个方法都变得很清晰,而且整体架构也比前两个单元简单,都是单个方法的算法优化。而且出bug的时候也非常容易确定具体位置,我们主要做的就是优化,维护,降低时间复杂度。
同时本单元也让我体会到了各种测试,以前只是听过那么多测试方法,但是在这单元的作业中,我也是利用了各种测试,共同保证了程序的正确性。
对于JML,我个人觉得其实还挺好玩的,在本届JML中可以调用之前的方法,也降低了阅读JML的难度。有了JML,确实可以规范好每个方法的行为,减少了出现错误的概率,让程序更加可靠。